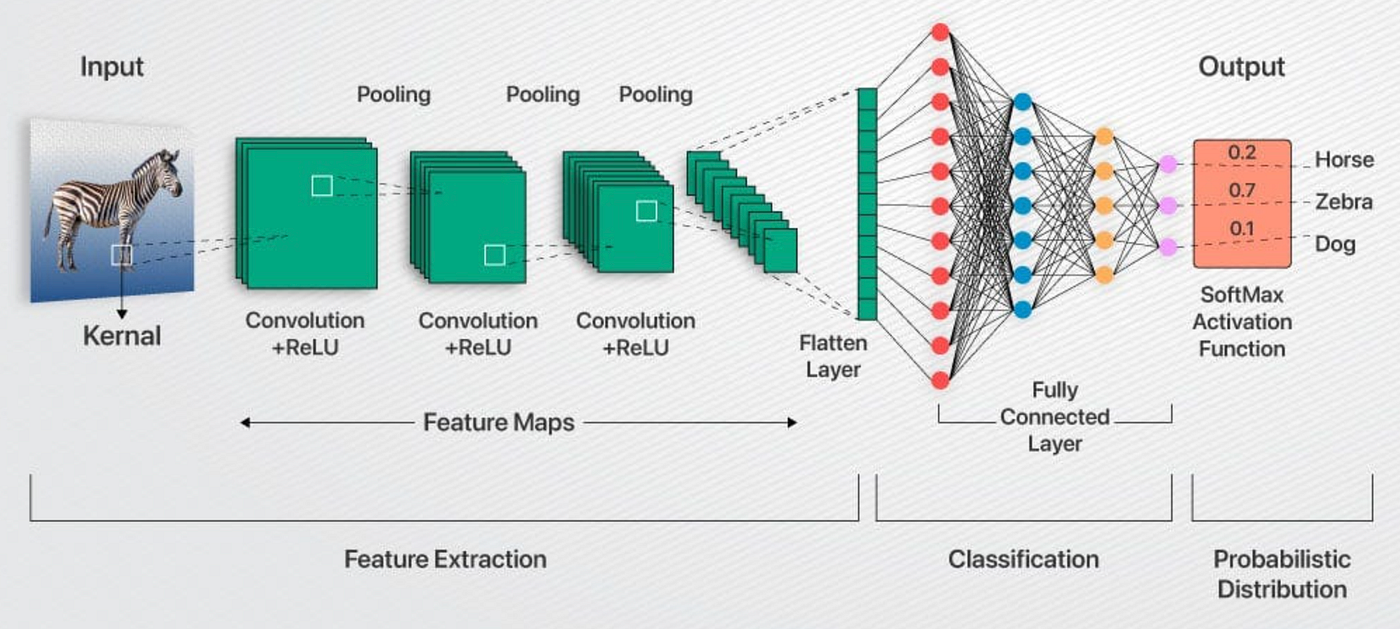
One of the projects I'm most proud of is the modular convolutional neural network pipeline I built entirely from scratch in Python. I'd been using deep learning frameworks for a while and kept feeling like I was missing something by not knowing what was actually happening under the hood. It's easy to call a PyTorch function and get a result, but that abstraction only takes you so far. So I decided to build my own, and that decision turned out to be one of the most valuable learning experiences I've had as a developer.
The core of the project involved writing original code for every major component of a CNN: populating kernel matrices, traversing input matrices, computing convolutions, and handling pooling operations. I also implemented the loss function, derived and coded the gradient of the loss, and wrote the parameter update logic myself. Going through that process developed a level of intuition about backpropagation and gradient descent that I don't think I could have gained any other way. Working through the calculus and debugging the implementation by hand really solidified the underlying theory in a way that simply using a framework does not.
I also put considerable effort into making the pipeline performant. I leveraged CUDA to parallelize the large-scale matrix computations on the GPU, which made a substantial difference in training time. This required learning how GPU memory works and how to manage it efficiently, which becomes critical when working with large input matrices. I used PyTorch tensors as the backbone for these operations, getting comfortable with more advanced aspects of tensor manipulation such as reshaping tensors to enable broadcasting, vectorizing computations to improve performance, and implementing batching using vmap.
One design decision I'm particularly satisfied with is that I built the pipeline to be modular, making it straightforward to configure and swap out hyperparameters without restructuring the codebase. Building every component from the mathematics to the GPU memory management gave me a much more complete understanding of how CNNs function than I would have developed working within an existing framework.
The goal of this project was to predict any player's next box score and the outcome of an NBA game based on their next opponent and historical box score data. Box scores were analyzed in an individual context rather than a team context as a team's roster could be variable across a season. Especially when analyzing a sequence of matchups between two set teams, the rosters of either team could look entirely different across just a sequence of 5. This was a time series forecasting problem as I wanted to model the player's performance with respect to time as well as the performance of other players and other context features.
For any given player, the model had to forecast his box score based on the past games of the player, his teammates, and his opponents. Additional context features were incorporated into the series to account for factors like potential fatigue from strenuous schedules, psychological pressure from risk of elimination, and travel.
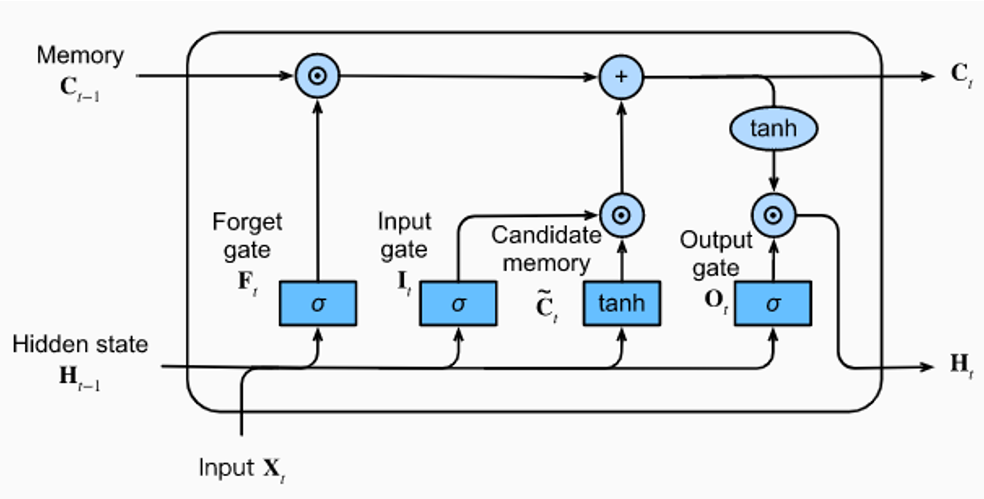
For analyzing the time series, I used an LSTM. To account for roster inconsistency, the sequences were compiled by gathering the last several games of the player of interest and a configurable number of top opponents based on minutes played, irrespective of what team they were playing for during those games. The LSTM encoded the sequences for the player of interest, teammates, and opponents separately. The opponent and teammate embeddings were processed by an attention mechanism to learn which players were the most impactful to the player's performance before all three embeddings were concatenated. The concatenated embedding was then fed into an MLP network to predict the box score. This improved the model's ability to map a player's performance to the performance of others. To account for context, the context data was concatenated to the input vectors that were fed into each LSTM.
The input vectors for the LSTMs were obtained using nba_api, an API for accessing stats from nba.com. To represent the performance of each player, I included the entire box score for all players. While some of these stats were potentially redundant, all of them were included in the initial version of the model with the intention of testing for redundancy after the architecture proved to be effective. I added indicators for back-to-back games, number of rest days, travel distance and time zone switches, injuries, roster continuity, playoff games, and elimination scenarios. I also added two stats that the box score does not capture directly: true shooting percentage and offensive and defensive rebound rate.
I developed a CUDA-based matrix multiplier to understand GPU memory management and see how fundamental operations drive machine learning performance. Matrix multiplication is at the core of nearly every neural network computation, from forward passes to backpropagation, so building an optimized implementation seemed like the right way to understand what's really happening when those frameworks compute results. I wanted to get comfortable with the memory hierarchy that makes GPUs powerful and learn how to write code that respects it.
The kernel uses a tiled approach where thread blocks cooperatively load small chunks of matrices into shared memory before performing calculations. This strategy significantly reduces memory bandwidth requirements compared to naive implementations where every thread independently fetches data from global memory. Getting the synchronization right wasn't trivial. Properly using __syncthreads() required careful thinking about when threads need to wait for each other, and working through that problem gave me genuine insight into how GPU memory hierarchies function.
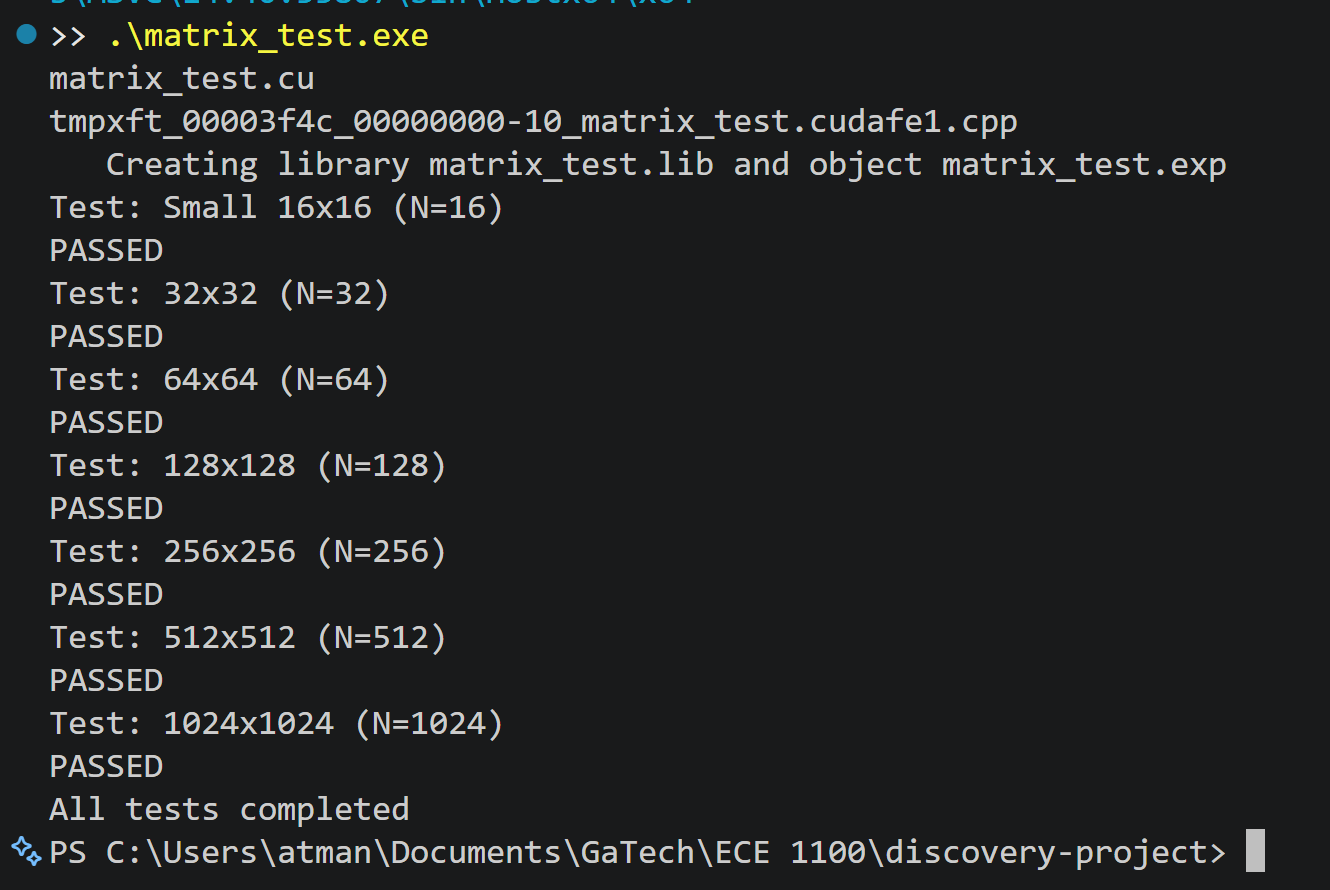
I built a comprehensive test framework that validated GPU results against CPU reference implementations across different matrix sizes. Writing that verification code taught me about floating-point precision trade-offs and why rigorous testing matters when optimizing code. Every component of the project, from memory management to thread coordination, connected abstract concepts to practical implementation.
That hands-on experience building something performant from first principles developed an intuition about parallel computing that I couldn't have gained any other way. Building every component from the kernel implementation to the GPU memory management gave me a much more complete understanding of how GPUs function than I would have developed just reading about it.